Optimize amount of read data with Acumatica and LINQ
Hi everybody,
today I want to share quite useful post for cases, if you'll need to get some limited dataset from Acumatica database.
Take a look on the code below:
public PXAction<SOOrder> FilterColumns; [PXButton] [PXUIField(DisplayName = "Filter Columns")] public IEnumerable filterColumns(PXAdapter adapter) { var arTrans = SelectFrom<ARTran>.View.Select(Base). Where(t => t.Record.TranType == "CRM") .Select(r => new { r.Record.TranType, r.Record.RefNbr, r.Record.CuryTranAmt }); Base.CurrentDocument.Current.DocDesc += arTrans.Sum(a => a.CuryTranAmt).ToString(); Base.CurrentDocument.Cache.Update(Base.CurrentDocument.Current); return adapter.Get(); }
As you may notice, it reads from table ARTran, so nothing special. But tell me please, what columns will be read? All of ARTran columns? Three columns? You'll be surprised to learn, that only one column will be read. And that will be aggregated column.
Below goes a screenshot from SQL Server profiler:
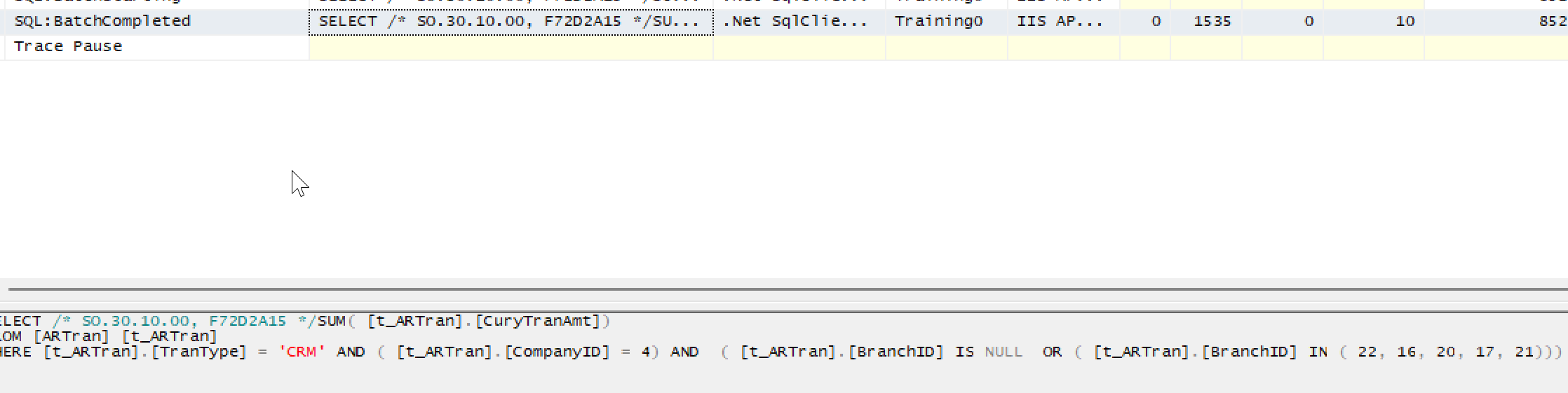
as you see, in the output, Acumatica ORM generated single value and single column.
Summary
If you need optimize reading from database, then consider to use ordinary LINQ, as Acumatica ERP become more efficient.
If you're looking to take your Acumatica ERP customization to the next level, we're here to help! Whether you need tailored database queries, performance improvements, or any other custom solution, our expert team can make it happen.
Leave a request today, and let's explore how we can enhance your Acumatica platform to meet your specific needs. Don’t wait—unlock the full potential of your system now!