How To Parse Google Search Results
Hello everybody,
today I want to describe how to use C# for scrapping results.
For me it was surprising to see, that there is a stereotype that for scrapping the best tool or tools only to use are R, Python. And majority of people who needed functionality of parsing wanted that functionality in some of those languages. While I do agree that those are great languages, which really enhance toolbox of developer, I want to show also that in C# you can achieve similar results.
Below goes screenshot of C# program which sends request to google and receives result:
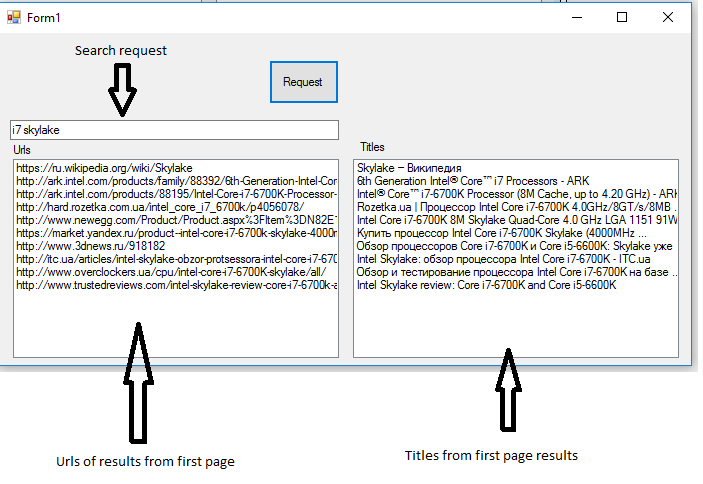
Application workflow is pretty simple.
- You enter search request. At screenshot you can see that search request was i7 skylake
- Press at button Request
- Application send request to google.
- Application parses respond from the first page from google and shows urls and titles of urls.
Below I also provide hear of that program:
Snippet
using System; using System.IO; using System.Net; using System.Text; using System.Windows.Forms; using NScrape; using HtmlAgilityPack; using System.Text.RegularExpressions; namespace WebRequesting { public partial class Form1 : Form { HtmlAgilityPack.HtmlDocument htmlSnippet = new HtmlAgilityPack.HtmlDocument(); public Form1() { InitializeComponent(); } private void btn1_Click(object sender, EventArgs e) { lstTitles.Items.Clear(); lstUrls.Items.Clear(); StringBuilder bufferForHtml = new StringBuilder(); byte[] encodedBytes = new byte[8192]; var urlForSearch = "http://google.com/search?q=" + txtSearch.Text.Trim(); var request = (HttpWebRequest)System.Net.WebRequest.Create(urlForSearch); var response = (HttpWebResponse)request.GetResponse(); using (Stream responseFromGoogle = response.GetResponseStream()) { var enc = response.GetEncoding(); int count = 0; do { count = responseFromGoogle.Read(encodedBytes, 0, encodedBytes.Length); if (count != 0) { var tempString = enc.GetString(encodedBytes, 0, count); bufferForHtml.Append(tempString); } } while (count > 0); } string sbb = bufferForHtml.ToString(); var processedHtml = new HtmlAgilityPack.HtmlDocument { OptionOutputAsXml = true }; processedHtml.LoadHtml(sbb); var doc = processedHtml.DocumentNode; foreach (var link in doc.SelectNodes("//a[@href]")) { string hrefValue = link.GetAttributeValue("href", string.Empty); if (!hrefValue.ToUpper().Contains("GOOGLE") && hrefValue.Contains("/url?q=") && hrefValue.ToUpper().Contains("HTTP")) { int index = hrefValue.IndexOf("&"); if (index > 0) { hrefValue = hrefValue.Substring(0, index); lstTitles.Items.Add(hrefValue.Replace("/url?q=", string.Empty)); string output = Regex.Replace(link.InnerText, ""\\.?", string.Empty); lstUrls.Items.Add(output); } } } } } }
If you like C#, you'll see, that program in general sends request, receives response, decodes result, and then parses url, and those, which follow certain criteria are added to listbox.
If you found this demonstration of using C# for web scraping insightful and are looking to leverage similar custom solutions within your Acumatica environment, we’re here to help! Whether you need tailored integrations, custom workflows, or specialized parsing tools, our team can bring your vision to life.
Leave a customization request today and let’s transform your Acumatica experience with powerful, bespoke solutions designed to meet your unique business needs. Don’t let stereotypes limit your tools—embrace the flexibility of C# and Acumatica to achieve exceptional results!
2 Comments
Alex said 2 years ago
That is a great code, however Google may block you for automated searches. How to overcome this limitation? And how would this code solve captcha?
docotor said 2 years ago
Yes, I understand that google can block and actually will block. In order to prevent blocking I as usually apply following options:
1. Use timer, in order to send requests not often.
2. With help of Webproxy class make connection via proxies.