How To Create Learning Set For Neural Network In Deeplearning4j
Hello everybody,
today I want to document one simple feature of Deeplearning4j library. Recently I had an assignment to feed into neural network for Deeplearning4j.
If your learning set is not big ( later I'll explain what big means ) then you can put all your data into INDArray and then based on that you can create DataSet. Take a look at fragments of XorExample.java:
1 // list off input values, 4 training samples with data for 2 2 // input-neurons each 3 INDArray input = Nd4j.zeros(4, 2); 4 5 // correspondending list with expected output values, 4 training samples 6 // with data for 2 output-neurons each 7 INDArray labels = Nd4j.zeros(4, 2);
Above Deeplearning4j team just reserved some small memory for learning.
Next goes filling information:
// create first dataset
// when first input=0 and second input=0
input.putScalar(new int[]{0, 0}, 0);
input.putScalar(new int[]{0, 1}, 0);
// then the first output fires for false, and the second is 0 (see class
// comment)
labels.putScalar(new int[]{0, 0}, 1);
labels.putScalar(new int[]{0, 1}, 0);
// when first input=1 and second input=0
input.putScalar(new int[]{1, 0}, 1);
input.putScalar(new int[]{1, 1}, 0);
// then xor is true, therefore the second output neuron fires
labels.putScalar(new int[]{1, 0}, 0);
labels.putScalar(new int[]{1, 1}, 1);
// same as above
input.putScalar(new int[]{2, 0}, 0);
input.putScalar(new int[]{2, 1}, 1);
labels.putScalar(new int[]{2, 0}, 0);
labels.putScalar(new int[]{2, 1}, 1);
// when both inputs fire, xor is false again - the first output should
// fire
input.putScalar(new int[]{3, 0}, 1);
input.putScalar(new int[]{3, 1}, 1);
labels.putScalar(new int[]{3, 0}, 1);
labels.putScalar(new int[]{3, 1}, 0);
After that they create DataSet with all inputs, outputs:
// create dataset object
DataSet ds = new DataSet(input, labels);
I will skip neural network creation and configuration because purpose of this post is just explain about locating in memory learning set.
What is big?
As I mentioned initially what is big amount of data in Deeplearning4j. I'll explain with example. RAM amount on my server is 256 Gb. Let's mark it with variable ramAmount.
I want to feed into memory 800 files, 2703360 bytes each. In total they will take 800 * 2703360 ~ 2 Gb.
But when I applied Xor approach to mine dataset I've continiously got following error message:
Exception in thread "main" java.lang.IllegalArgumentException: Length is >= Integer.MAX_VALUE: lengthLong() must be called instead
at org.nd4j.linalg.api.ndarray.BaseNDArray.length(BaseNDArray.java:4203)
at org.nd4j.linalg.api.ndarray.BaseNDArray.init(BaseNDArray.java:2067)
at org.nd4j.linalg.api.ndarray.BaseNDArray.<init>(BaseNDArray.java:173)
at org.nd4j.linalg.cpu.nativecpu.NDArray.<init>(NDArray.java:70)
at org.nd4j.linalg.cpu.nativecpu.CpuNDArrayFactory.create(CpuNDArrayFactory.java:262)
at org.nd4j.linalg.factory.Nd4j.create(Nd4j.java:3911)
at org.nd4j.linalg.api.ndarray.BaseNDArray.create(BaseNDArray.java:1822)
as far as I grasp from mine conversations with support Deeplearning4j attempts to do the following: create one dimensional array which will be executed on all processors ( or video cards ). In my case it wasn possible only and only when my learning set was not 800, but something around 80. That is far less then waht I wanted to use for learning.
How to deal with big data set?
After realizing problem I had again dig deeper into Deeplearning4j samples. I found very useful sample of RegressionSum. There they create data set with help of function getTrainingData. Below goes source code of it:
1 private static DataSetIterator getTrainingData(int batchSize, Random rand){ 2 double [] sum = new double[nSamples]; 3 double [] input1 = new double[nSamples]; 4 double [] input2 = new double[nSamples]; 5 for (int i= 0; i< nSamples; i++) { 6 input1[i] = MIN_RANGE + (MAX_RANGE - MIN_RANGE) * rand.nextDouble(); 7 input2[i] = MIN_RANGE + (MAX_RANGE - MIN_RANGE) * rand.nextDouble(); 8 sum[i] = input1[i] + input2[i]; 9 } 10 INDArray inputNDArray1 = Nd4j.create(input1, new int[]{nSamples,1}); 11 INDArray inputNDArray2 = Nd4j.create(input2, new int[]{nSamples,1}); 12 INDArray inputNDArray = Nd4j.hstack(inputNDArray1,inputNDArray2); 13 INDArray outPut = Nd4j.create(sum, new int[]{nSamples, 1}); 14 DataSet dataSet = new DataSet(inputNDArray, outPut); 15 List<DataSet> listDs = dataSet.asList(); 16 Collections.shuffle(listDs,rng); 17 return new ListDataSetIterator(listDs,batchSize); 18 19 }
As you can see from the presented code, you need to
- create one or more input arrays.
- Create output array.
- if you created more then one input arrays then you need to merge them in one array
- Create DataSet that has inputs array and outputs array
- Shuffle ( as usually this improves learning )
- Return ListDataSetIterator
Configure memory for class in intellij idea
If you have hope that adventures with memory were completed I need to disappoint you. There were not. Next step that is needed for Deeplearning4j is configuration of available memory for particular class. Initially I got an impression that this can be done via edition vmoptions file of In intellij idea. But that assumption is wrong. You'll need to configure memory for particular class like this:
1. select your class and choose Edit Configurations:
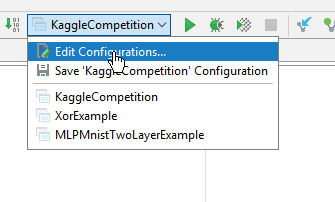
2. Set some memory like presented at screenshot:
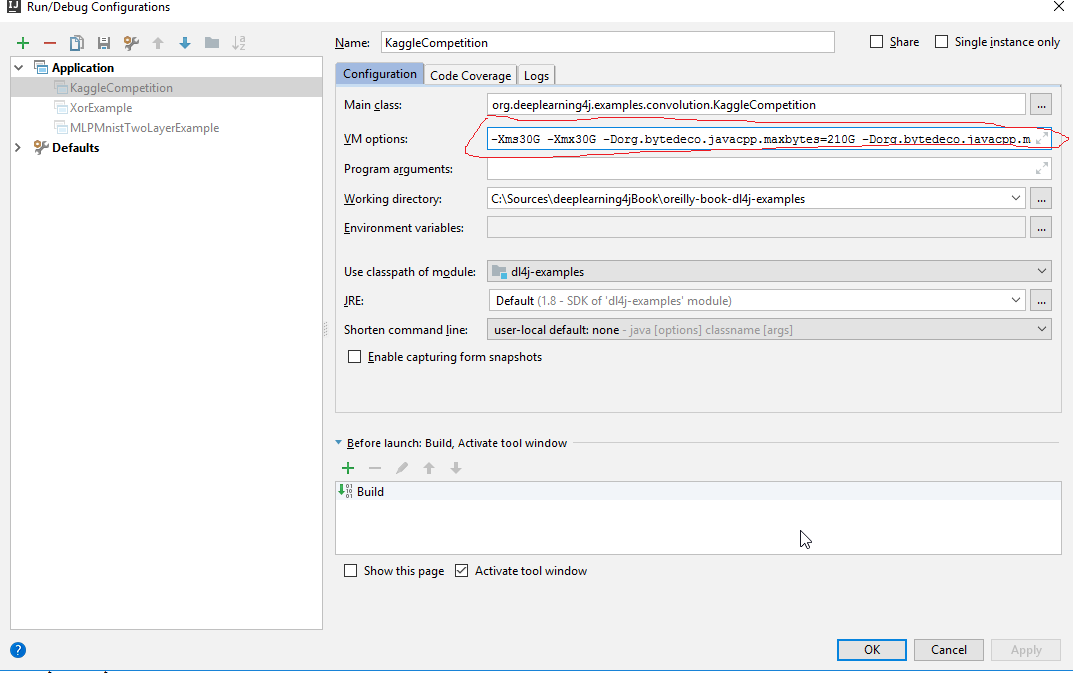
IN my case I've used following line for memory:
-Xms30G -Xmx30G -Dorg.bytedeco.javacpp.maxbytes=210G -Dorg.bytedeco.javacpp.maxphysicalbytes=210G
Keep in mind that parameters -Dorg.bytedeco.javacpp.maxbytes should be equal to -Dorg.bytedeco.javacpp.maxphysicalbytes.
One more final detail to keep in mind, you'll also will need to think about parameter batchsize that you feed into neural network while configuring MultiLayerNetwork.
Just as Deeplearning4j allows you to customize and optimize your neural network's memory usage and data handling, Acumatica offers unparalleled flexibility to tailor your ERP system to your unique business needs. Whether you're dealing with complex data sets or specific operational workflows, Acumatica's robust development framework ensures you can build the perfect solution.
If you’re looking to enhance your Acumatica experience with custom features or integrations, don’t hesitate to reach out! Leave a customization request today and let’s transform your Acumatica system into a powerhouse of efficiency and innovation. Your business deserves a solution as unique as your data—let’s make it happen!