How To Measure Quality Of Learning Part 2
Hello everybody,
today I want to add few more notes about measuring of quality of learning, but today about tasks of classification.
So, one of the ways can be measuring number of wrong answers. For example with usage of the following formula:
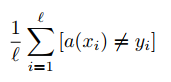
Imagine that your classification set has three possible labels: a (10 elements ), b ( 15 elements ), c ( 20 elements ). And let's say that your model wrongly classified 2 out of a, 3 out of b and 4 out of c. In that case following formula is applicable:
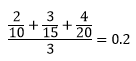
Historically it happend that in classification tasks it is common to maximaze function, while in regression learning vice versa.
Another common measurement of quality of classification is accuracy. Formula is like this:
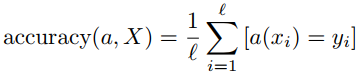
That is very simple measuremnt of quality, and it is widely used. But it has some side effects. Let's consider few examples.
Unbalanced samplings
Consider following example. Let's say you have 1000 elements in sampling. And in your sampling 950 elements belong to class a, and 50 elements belong to class b. And let's say you've built a model that gives as output always class a. That model is useless, because it doesn't reproduce anything in data. But accuracy of that constant algorithm will be 0.95. But let's say you still want to use accuracy for measurement. What kind of output can be considered as reasonable? In our sample accuracy should be in range [0.95, 1], and not [0.5, 1] as in case of binary classification.
Consider another example. Let's say you want to build a model which will give advice: to give loan or not to give a loan. And lets say you have two models:
Model 1:
- 80 loans returned
- 20 loans not returned
Model 2:
- 48 loans returned
- 2 loans not returned
Which model is better? What is worse? Give loan to bad customer, that will not return loan, or not give loan to good customer that can return loan? Looks like littlbe bit more characteristics are needed. Accuracy doesn't take into account value of error. Something more is needed to be taken into account. Also adding of precision allows us not to treat all objects as elements of one class, because in that case we will get increase of False Positive.
Error matrix
Consider following error matrix:
| y = 1 (belongs to class 1) | y = -1 ( belongs to class 2 ) | |
| a(x) = 1 |
True Positive (TP) Correct trigering |
False Positive (FP) Wrong triggering |
| a(x) = -1 |
False Negative (FN) Incorrect skipping |
True Negative (TN) Correct skipping |
So, we have two columns: y=1 and y=-1. In case if model treat element as something belonging to y=1 we can say that model worked. If modle treat element as belonging to y = -1 we can say that model skipped element. In such a way we have two kinds of errors: inoccrect triggering and wrong skipping.
Consider then following example. Let's say we have 200 objects: 100 belongs to class 1 and another 100 belongs to class -1. And take a look at following confusion matrixes:
Model 1:
| y = 1 | y = -1 | |
| a1(x) = 1 | 80 | 20 |
| a1(x) = -1 | 20 | 80 |
Model 2:
| y = 1 | y = -1 | |
| a2(x) = 1 | 48 | 2 |
| a2(x) = -1 | 52 | 98 |
And question: which one is better? Model 1 or model 2?
For such purposes we can use two characteristics: precision and recall. For me personally recall can be also characteristics of completeness of memorization.
Formula for precision:
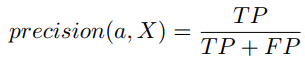
and for recall:
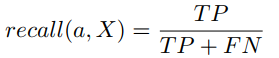
now if to put those values into calculation we'll receive the following:
precision(a1,x) = 0.8
recall(a1,x) = 0.8
precision(a2,x) = 0.96
recall(a2,x) = 0.48
From those standpoint we see that second model is more precise but with sacrifice of recall. In other words if second model triggered we can be sure with bigger degree of confidence in correctness of it's result. Or in another words you can interpret precision as part of objects that classifier interpret as positive and they are really positive, while recall says to you which part of objects of class 1 model really found.
How to use precision and recall?
And now what? How can you use precision and recall? For example like this. You have a task of loan scoring. It can sound like: un returned loans number should be smaller then 5%. It terms of todays formula it looks like:
precision(a, X) ≥ 0.95. And your task is to maximize recall.
Another example. You should fine not less then 80% of sick people in some set. In terms of formulas it look like this:
recall(a, X) ≥ 0.8 , and you maximize precision.
Unbalanced sampling
| y = 1 | y = -1 | |
| a(x) = 1 | 10 | 20 |
| a(x) = -1 | 90 | 1000 |
imagine that you've get result as displayed in table above. It has wonderful accuracy:
accuracy(a, x) = 0.9
but precision and recall help you to see real picture:
precision(a, x) = 0.33
recall (a, x) = 0.1
Should you use this model? Definetely not!!!
Are you looking to optimize your Acumatica system to achieve precision and recall in your business processes, just like in classification tasks? Whether it’s streamlining loan scoring, improving decision-making, or enhancing data accuracy, customizing Acumatica can help you maximize efficiency and minimize errors.
Leave a customization request today and let our experts tailor Acumatica to your unique business needs. Don’t settle for generic solutions—achieve the perfect balance of precision and recall for your operations.